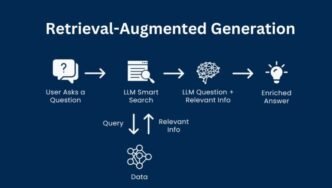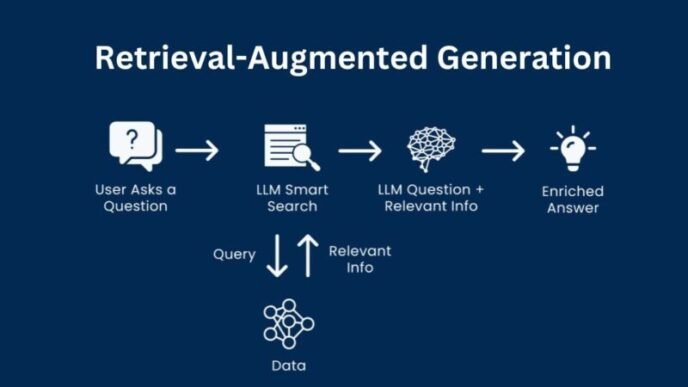
Principal Component Analysis (PCA) is a statistical method used to reduce the dimensionality of data while retaining most of its variability. It transforms high-dimensional data into a lower-dimensional space, making it easier to analyze and visualize. PCA is widely used in fields like machine learning, data analysis, and bioinformatics for simplifying datasets without significant loss of information.
In essence, PCA identifies patterns in data and expresses it in a way that highlights similarities and differences. This process not only simplifies computations but also helps uncover hidden relationships.
Why Use Principal Component Analysis?
Modern datasets often have numerous features, many of which may be redundant or irrelevant. This makes data processing computationally expensive and harder to interpret. PCA addresses these challenges by:
1. Reducing Dimensions: Compresses datasets without losing much information.
2. Removing Redundancy: Identifies and eliminates correlated variables.
3. Improving Performance: Speeds up machine learning algorithms by reducing feature space.
4. Enhancing Visualization: Allows visualization of high-dimensional data in 2D or 3D.
For instance, imagine a dataset with hundreds of features. PCA can reduce it to a few principal components while retaining most of its variance.
How Does PCA Work?
PCA works by finding new axes, called principal components, which maximize the variance in the data. Here’s a step-by-step explanation:
1. Standardize the Data
Data features may have different scales. Standardization ensures each feature contributes equally by rescaling them to have a mean of 0 and variance of 1.
Formula:
z = (x – μ) / σ
Where:
• : Original value
• : Mean of the feature
• : Standard deviation of the feature
2. Compute the Covariance Matrix
The covariance matrix represents how features vary together.
Formula:
cov(X, Y) = Σ((xᵢ – μₓ) * (yᵢ – μᵧ)) / (n – 1)
3. Calculate Eigenvectors and Eigenvalues
Eigenvectors define the direction of the principal components, while eigenvalues represent their magnitude (variance explained by the component).
4. Sort Principal Components
Arrange eigenvectors in descending order of their eigenvalues. This ranks components by their significance.
5. Project Data onto Principal Components
Transform the data to align with the principal components, creating a lower-dimensional representation.
Formula:
Y = X * W
Where:
• : Transformed data
• : Original data
• : Matrix of principal component vectors
Python Implementation of PCA
Here’s how you can perform PCA using Python and the scikit-learn library:
<pre>
<code>
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Example dataset
data = np.array([[2.5, 2.4],
[0.5, 0.7],
[2.2, 2.9],
[1.9, 2.2],
[3.1, 3.0],
[2.3, 2.7],
[2.0, 1.6],
[1.0, 1.1],
[1.5, 1.6],
[1.1, 0.9]])
# Standardize the data
scaler = StandardScaler()
data_std = scaler.fit_transform(data)
# Apply PCA
pca = PCA(n_components=2)
principal_components = pca.fit_transform(data_std)
# Explained variance
print(“Explained Variance:”, pca.explained_variance_ratio_)
# Principal components
print(“Principal Components:”, principal_components)
</code>
</pre>
Applications of PCA
1. Image Compression
PCA reduces the dimensions of image data by identifying patterns in pixel values.
2. Genomics
Used to analyze gene expression data, highlighting significant variations.
3. Marketing Analytics
Identifies important customer behavior trends by reducing survey features.
4. Finance
Analyzes stock market data to detect dominant trends.
5. Machine Learning
Improves algorithm performance by reducing input feature space.
Advantages of PCA
1. Efficient Dimensionality Reduction:
PCA effectively reduces large datasets into manageable sizes.
2. Noise Elimination:
By focusing on significant components, PCA removes noise.
3. Better Interpretability:
Simplifies complex datasets for easier interpretation.
Limitations of PCA
1. Linear Assumption:
PCA assumes linear relationships, making it less effective for non-linear data.
2. Information Loss:
Some variance is inevitably lost during dimensionality reduction.
3. Scaling Dependency:
PCA requires standardized data for meaningful results.
PCA vs. Other Dimensionality Reduction Techniques
Aspect PCA t-SNE Autoencoders
Approach Linear transformation Non-linear mapping Neural networks
Visualization Good for 2D or 3D Superior in 2D Limited
Interpretability High Low Medium
Scalability Fast Slow Computationally expensive
When to Use PCA
• When data has many features and may suffer from the “curse of dimensionality.”
• For noise reduction in datasets with irrelevant or redundant variables.
• To visualize high-dimensional data for exploratory analysis.
Further Reading
• PCA on Scikit-learn Documentation
• Understanding Eigenvectors and Eigenvalues
• Principal Component Analysis Explained
Conclusion
Principal Component Analysis is a cornerstone technique in data analysis and machine learning. Its ability to reduce dimensionality while preserving essential patterns makes it indispensable for large-scale data. Whether you’re exploring data or improving machine learning workflows, PCA is a powerful tool to have in your arsenal.