Machine learning is evolving rapidly, and among its most potent techniques is ensemble learning. It combines multiple models to achieve superior accuracy, robustness, and generalization. Whether you’re tackling classification, regression, or anomaly detection, ensemble methods provide a structured way to maximize predictive performance. Let’s dive deep into the world of ensemble algorithms, explore their types, benefits, and how they work, and uncover how you can implement them effectively.
What is Ensemble Learning?
Ensemble learning is a technique in machine learning where multiple models, often called weak learners, are combined to create a more powerful model, referred to as a strong learner. The fundamental principle is that a group of diverse models can collectively make better predictions than individual models. By combining their strengths and compensating for their weaknesses, ensemble methods significantly reduce errors caused by overfitting, bias, or variance.
Why Use Ensemble Methods?
• Higher Accuracy: Combining multiple models reduces individual errors and produces more reliable results.
• Improved Robustness: Less sensitivity to outliers and noisy data ensures consistent performance.
• Reduction of Overfitting: By averaging multiple models, ensembles generalize better to unseen data.
• Flexibility: Can integrate diverse models like decision trees, neural networks, and support vector machines (SVMs).
Key Types of Ensemble Learning
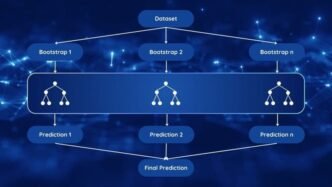
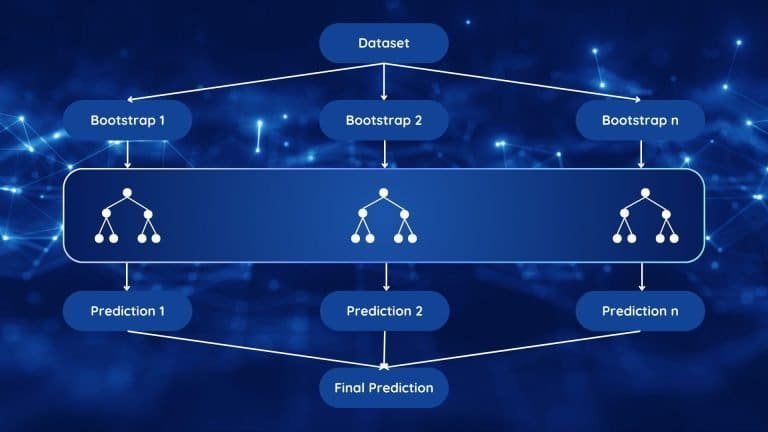
1. Bagging (Bootstrap Aggregating)
Bagging reduces variance by training models on randomly sampled subsets of data.
How it works:
• Sampling: Creates multiple bootstrap samples (subsets with replacement) from the training data.
• Training: Each subset trains a model independently, typically a decision tree.
• Aggregation: Predictions are averaged (regression) or voted on (classification) to produce the final output.
Popular Algorithm:
Random Forest is the most widely used bagging technique. It builds multiple decision trees and introduces additional randomness by selecting random features for splitting nodes. This makes it robust and less prone to overfitting.
2. Boosting
Boosting tackles bias by training models sequentially, where each model improves upon the errors of the previous one.
How it works:
• Weighted Samples: Misclassified samples get higher weights, so subsequent models focus on them.
• Sequential Training: Models are added iteratively, each reducing the cumulative error.
• Combination: Predictions from all models are combined using weighted voting or averaging.
Popular Algorithms:
• AdaBoost: Focuses on misclassified samples and adjusts their weights iteratively.
• Gradient Boosting Machines (GBM): Optimizes a loss function using gradient descent.
• XGBoost: Adds regularization, handles missing values, and speeds up computation.
• LightGBM: Grows trees leaf-wise for faster training and better efficiency.
• CatBoost: Designed for categorical data, simplifying preprocessing.
3. Stacking
Stacking, or stacked generalization, combines multiple models by using a meta-model to make the final prediction.
How it works:
• Base Models: Different algorithms (e.g., decision trees, SVMs, neural networks) are trained on the same dataset.
• Meta-Model: A higher-level model is trained on the predictions of the base models.
• Diversity: This approach leverages the strengths of various algorithms to boost performance.
Why Use Stacking?
It excels in combining diverse models, often outperforming individual models or simpler ensembles like bagging or boosting.
4. Voting
Voting is one of the simplest ensemble techniques, where predictions from multiple models are aggregated.
Types:
• Hard Voting: Chooses the class predicted by the majority of models.
• Soft Voting: Averages the probabilities from all models and selects the class with the highest probability.
Best Use Case: When individual models are strong yet diverse, voting can be a quick and effective ensemble method.
How Ensemble Learning Balances Bias and Variance
The bias-variance tradeoff is at the heart of ensemble learning:
• Bagging: Reduces variance by averaging predictions, making the model less sensitive to fluctuations in the training data.
• Boosting: Reduces bias by focusing on difficult-to-predict samples and refining the model iteratively.
This balance ensures that ensemble methods generalize well, avoiding overfitting or underfitting.
Popular Ensemble Algorithms
1. Random Forest: A bagging-based algorithm that builds multiple decision trees and averages their predictions. It handles high-dimensional data effectively and provides feature importance scores.
2. AdaBoost: A boosting algorithm that adjusts sample weights to prioritize harder-to-classify examples, improving overall accuracy.
3. Gradient Boosting Machines (GBM): Sequentially optimizes a loss function using gradient descent, offering flexibility for various tasks.
4. XGBoost: An optimized version of GBM with faster computation, regularization, and parallel processing.
5. LightGBM: Focused on speed and efficiency, it’s ideal for large datasets with high-dimensional features.
6. CatBoost: Excels with categorical features, requiring minimal preprocessing.
Implementing Ensemble Learning in Python
Here’s a quick example using Random Forest and AdaBoost on the Iris dataset:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier, AdaBoostClassifierfrom sklearn.metrics import accuracy_score# Load datasetdata = load_iris()X, y = data.data, data.target# Split dataX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Random Forestrf = RandomForestClassifier(n_estimators=100, random_state=42)rf.fit(X_train, y_train)rf_pred = rf.predict(X_test)# AdaBoostada = AdaBoostClassifier(n_estimators=100, random_state=42)ada.fit(X_train, y_train)ada_pred = ada.predict(X_test)# Accuracyprint("Random Forest Accuracy:", accuracy_score(y_test, rf_pred))print("AdaBoost Accuracy:", accuracy_score(y_test, ada_pred))This demonstrates how ensemble methods can be applied seamlessly using Python libraries like scikit-learn.
Real-World Applications of Ensemble Learning
1. Finance: Fraud detection, credit scoring, and risk analysis.
2. Healthcare: Disease diagnosis, patient outcome prediction, and medical image analysis.
3. Marketing: Customer segmentation, recommendation systems, and churn prediction.
4. Engineering: Fault detection and predictive maintenance.
5. E-commerce: Personalized recommendations and dynamic pricing.
Advantages and Disadvantages of Ensemble Learning
Advantages:
• Boosts prediction accuracy.
• Reduces sensitivity to data noise.
• Provides robust generalization.
Disadvantages:
• Computationally expensive.
• Difficult to interpret compared to standalone models.
Conclusion
Ensemble machine learning algorithms are transformative tools that combine the predictions of multiple models to achieve superior results. From bagging methods like Random Forest to boosting techniques like XGBoost and versatile approaches like stacking, ensembles offer immense flexibility and power. Whether you’re dealing with noisy datasets, complex relationships, or high-stakes applications, ensemble methods provide a reliable path to success. Start implementing these methods in your projects today and experience the enhanced performance firsthand!